lwan http 服务器
简介
服务器端程序的设计模式一般比较固定,目前主要有两种主要的解决方式,一种多进程方式(进程池),另外一种多线程的方式(线程池)(P.S:请忘掉一个连接或一个业务fork一个进程,或起一个线程的方式,系统开销太大),两种方式都采用了非阻塞io,多路复用(P.S:Linux平台为最高效的epoll,新型api,如signalfd, timerfd, eventfd等,也可以进行epoll)。
对于多进程的模式,有些实现是,起一个主进程进行监听和管理,再起N个(N=cpu个数)业务进程,当主进程accept成功后,根据一定的业务逻辑,将fd发送到业务进程(P.S:发送方式用socketpair,参考:sock.c unix_domain_send_fd和unix_domain_recv_fd),业务进程对接收到到fd进行epoll。对于多进程,另外一些实现是,起N个(N=cpu个数)业务进程,同时N个进行地位同等,同时进行epoll,listen,accept等(P.S:多进行进行监听将引起群惊效应,但只有一个进程accept成功)。而多线程的模式,则和多进程模式类似,有一个主线程进行监听和管理,再起N个(N=cpu个数)业务线程,并将业务线程的调度级别设置为系统级别,这点非常重要,各个业务线程程进行进行epoll。
多进程和多线程并无本质区别,多线程的优点个人看来,数据都在整个进程空间,线程内数据都可以共享,需要留意共享数据的互斥访问,缺点就是调试起来稍微麻烦,而多进程的优点在于个人看来,调试相对多线程方便,缺点就是不方便运维。(P.S:旧同事入职一家导航的公司,他们的网络框架就是多线程模式,而公司的,多数是多进程模式。旧同事提起,所以现在再回头看看lwan, 当时只是看,没记录下来,现在重新记录一下)
lwan是个非常轻量级的http服务器(P.S:检验你是否掌握了C语言的标准,是否能完整的实现一个http服务器),代码量只有2W多行,比起成熟稳定的nginx代码量少太多了,当然功能也少很多。lwan在16年5月份左右一段时间在C语言项目排行榜star增加数排前列。个人觉得,lwan,它采用多线程模式,遵循了高并发服务设计的最基本模式,自己设计一个比较有特色的trie树的实现,可扩展的模块编写,同时创新的使用了协程(协程,自己在很久之前也关注过,参考: coroutine协程),这是最大的特点。当然,到目前为止,它还不稳定,从自己关注提出的第一个issue, 还有很多BUG,代码有一些不好的风格(如相对比较多的goto语句,一言不合就abort)。尽管如此,它还是一个非常值得学习的web服务器。下面简单粗略回顾下lwan,详细了解的话,参考代码,自己也fork了一份,加了部分注释lwan。(P.S:自己叫别人去学习,没理由自己忘记了)
大致工作流程
lwan的工作模式是非常典型的多线程模型,粗略画一下它的工作流程:
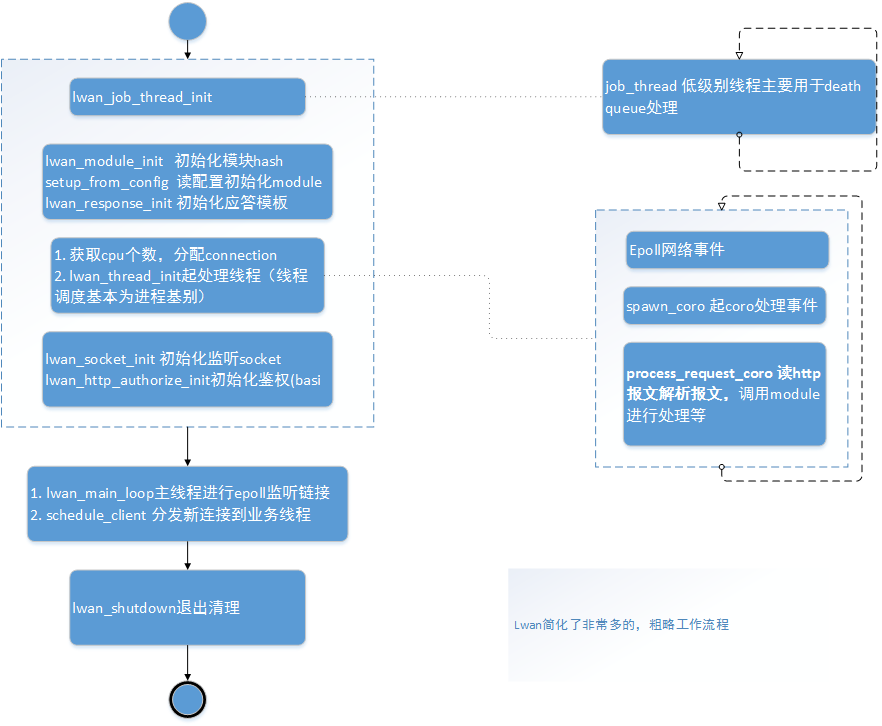
pthread_barrier_*这种数据结构,pthread_barrier_*其实只做且只能做一件事,就是充当栏杆(barrier意为栏杆)。形象的说就是把先后到达的多个线程挡在同一栏杆前,直到所有线程到齐,然后撤下栏杆同时放行。1)init函数负责指定要等待的线程个数;2) wait函数由每个线程主动调用,它告诉栏杆“我到起跑线前了”。wait执行末尾栏杆会检查是否所有人都到栏杆前了,如果是,栏杆就消失所有线程继续执行下一句代码;如果不是,则所有已到wait的线程停在该函数不动,剩下没执行到wait()的线程继续执行;3)destroy函数释放init申请的资源。
job线程在每一次循环调用sleep类的函数,这类函数有个致命的缺点,那就是不能响应信号,这就是导致lwan退出非常慢的原因。使用pthread_cond_wait可以避免该问题,已经修改,并进行了pull request:quick quit optimize。业务处理线程里面全部使用协程进行处理。
数据结构
一般程序,使用比较多的两个数据结构一个是list链表,另外一个是hashtable。list没有太多可讲的,而hashtable的实现,在这里可能也不是最优的。hashtable比较高效,而且经过大量检验的是redis的实现方式,推荐看这个,公司内部使用的库也是修改这个而来。网上对dict.c的分析很多,如:Redis 源码分析(1):字典和哈希表(dict.c 和 dict.h)。这里不累赘了,大体来说:hash 的典型实现方法,定义一个假如长度为len的数组,每个数组里面为leaf的节点,leaf节点为一链表结构。插入和查询就是,先计算key的hash,hash值取模len,得出数据所在的位置,添加到leaf节点后(插入),或者在从leaf链表里面遍历(查询,由于hash冲突),得到最终的结果。redis的dict包括两个这个样的hashtable,首先插入数据从0号hashtable插入,插入时创建,当0号hashtable增长到一定的程度或比例,那么就会创建1号hashtable,并将0号hashtable迁移到这个hashtable,如果正在发生迁移,那么新插入的数据就会插入1号hashtable,0号到1号hashtable的迁移是分摊到dict的每个操作之中的,并非采用集中式的迁移。当0号hashtable全部迁移到1号hashtable时,那么将0号hashtable删除,并将1号hashtable变为0号hashtable,1号hashtable变为NULL。然后在重复这样一个过程。
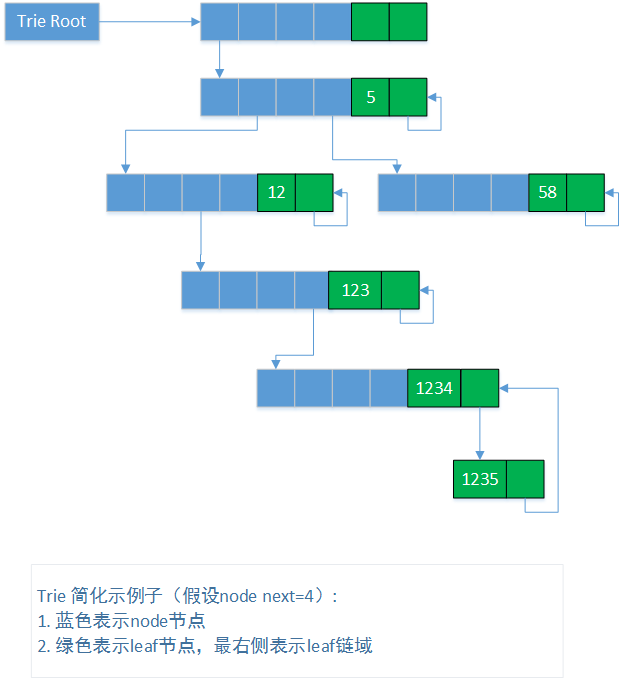
trie树是这里的另外一个重要的数据结构,很多web框架都严重依赖这种数据结构,个人觉得,这里实现的trie还是比较高效的:
|
|
比如,5,58,12,123,1234,12345在内存的存储情况(简化,假设struct lwan_trie_node *next[4]):
协程coro
业务处理线程里面全部使用协程进行处理的。协程应该属于lwan的核心了。协程可以参考coroutine协程,里面描述这里的有很大区别,但本质上都是都对context不同程度封装,或用汇编,或直接用系统函数。这里的coro定义了一个struct coro_defer_array defer;,用于connection超时或协程被清理时,内部资源的清理。具体协程不再详述。
协程本身概念并不难复杂,如果熟悉这种编程模式,那么非阻塞编程模式将可以用顺序编程的方式来思考,对程序员的思考的角度和业务逻辑的理解将有很大的提升(非阻塞的方式时,当业务流程需要进行阻塞时,比如需要连接第三方系统请求数据,那么业务当前的状态可能需要保存下来,当第三方系统应答时,再恢复状态,进行下一步处理,这样,业务流程就变成一段一段的了)。但是协程并没有大规模的使用,风云也曾介绍过,在推广协成概念时,遇到了很多问题(具体出处已忘记)。
使用协程必须适当评估程序STACK的大小,lwan里面是固定定义为#define PTHREAD_STACK_MIN 16384,协程分配的STACK为((3 * (PTHREAD_STACK_MIN)) / 2)或#define CORO_STACK_MIN (5 * (PTHREAD_STACK_MIN)),这样那么如果在协程切换函数里面定义一个比较大的临时变量,如char tmp[1024000]那么程序必挂了,因为栈溢出了。所以使用协程需要考虑STACK或考虑动态分配内存,动态分配内存还需要考虑释放问题(参考 lwan-coro.c coro_defer)。另外一个问题是,程序coredump时,用gdb进行调试,发现用bt进行调用堆栈查看时,有部分是乱的,不方便问题定位。我想这些有可能是协程没有被大规模推广的原因之一吧?
模块处理
lwan通过模块进行自身的扩展,自己本身也实现了一些模块。lwan-mod开头的文件都是它的模块。个人编写模块,只有实现相关的函数,直接编译成动态库即可。
|
|
自己实现一个helloworld模块可参考:helloworld
配置文件
lwan提供的配置文件,并没有覆盖全部的配置,下面从代码中提取的配置文件,供参考下(见国不少开源项目采用这种配置格式,但貌似没有具体定义这是那种格式,所有自己叫这种格式为tson,并写了一个简单解析的代码,参考tson):
|
|
其他
这里只是简单过一些lwan最基本的东西,没有详细的过里面的其他方面,仔细分析的话还有很多东西可以学,这里不再罗列了,暂时先这样。